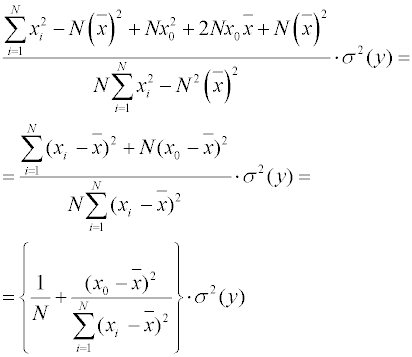|
|
ЧИСЛЕННЫЕ МЕТОДЫ И ПРОГРАММИРОВАНИЕ Материалы к лекционному курсу Лектор – ст. преп. Щербаков И.Н. Регрессионный анализ. Метод наименьших квадратов (МНК)Экспериментальное исследование зависимости физических величин, влияния условий на свойства и поведение исследуемых систем и соединений является весьма важной задачей в области химических исследований. Эта задача возникает в самых различных областях химии и позволяет решать многие проблемы, например: 1) Задача построения калибровочных зависимостей, по которым можно прогнозировать значение условий, которые обеспечивают определенный результат. 2) Определение важных физико-химических характеристик системы – например, зависимость свободной энергии системы от температуры будет линейной, а ее наклон равен изменению энтропии системы с отрицательным знаком. 3) Еще одна задача – сжатие (компактизация данных), когда подобранная функция используется для описания (аппроксимации) огромного массива экспериментальных данных (например, зависимость теплоемкости от температуры можно представить в виде функции, и в справочниках приводят не экспериментальную таблицу зависимости Cp от T, а коэффициенты выбранной функции). 4) Аппроксимация экспериментальных данных функцией с целью поиска точек минимума (максимума) – задача оптимизации. 5) И многие другие Настоящее учебно-методическое пособие посвящено рассмотрению основного подхода к регрессионному анализу – методу наименьших квадратов (МНК). Регрессионный анализ методом наименьших квадратов (МНК) В области естественных наук, в том числе и химии, важной задачей является исследование взаимосвязи физических величин, то есть поиск ответа на вопрос: как влияет изменение одной величины (или, в общем случае, нескольких) на значение, принимаемые другой. Для экспериментального решения задачи необходимо провести ряд экспериментов, в которых величины, чье влияние исследуется (независимые переменные) принимают заданные экспериментатором (различные) значения, а значения физической величины, чья зависимость исследуется (зависимая переменная) измеряется в результате проведения того или иного эксперимента. Это можно представить следующей схемой, где экспериментальная установка представляет собой некий «черный ящик», который может "выдавать" значение величины y в зависимости от заданных значений независимых переменных.
Пусть имеется k
независимых переменных (факторов),
Таблица 1
Последний столбец представляет собой статистически обработанные выборочные средние результатов проведения параллельных наблюдений для каждого сочетания значений независимых переменных в соответствующей строке таблицы. xij – это значение фактора с номером i (xi) в j-ом эксперименте. Иными словами, в результате экспериментального исследования функциональной зависимости получается таблично заданная функция, то есть функция, значения которой известны только в некоторых дискретных точках (узлах). Однако более удобным и информативным является запись зависимости величин через аналитические функции. Таким образом, необходимо решить задачу выбора аналитической функции, которая наилучшим образом будет описывать таблично заданную функцию (таблица 1). В общем виде она не решается, так как невозможно только из эксперимента определить вид математической функции, но можно решить более частную задачу подбора параметров, описывающих некоторую конкретную функциональную зависимость, чем и занимается регрессионный анализ. Сформулируем задачу регрессионного анализа в общем виде. Для произвольной математической модели вида необходимо подобрать такие
значения постоянных числовых параметров (коэффициентов регрессии)
Например, при построении калибровочных графиков, зависимость аналитического сигнала от концентрации носит линейный характер, т. е. функция y = f(x) описывается линейной математической моделью вида: y = b0 + b1 × x или y = b1 × x Здесь b0 и b1 – числовые параметры математической модели, которые необходимо определить, х – независимая, y – зависимая переменная. Одним из наиболее разработанных и
часто используемых алгоритмов регрессионного анализа является метод
наименьших квадратов (МНК). В рамках этого подхода параметры
математической модели
Здесь суммирование производится
по всем N экспериментальным точкам.
Регрессионный анализ с помощью МНК возможен при выполнении следующих необходимых условий: 1. yiэксп. есть случайные, нормально распределенные величины; 2. независимые переменные есть величины не случайные или, в крайнем случае, дисперсия независимых переменных является пренебрежимо малой по сравнению с дисперсией зависимой переменной. 3. дисперсии значений зависимой переменной для различных значений факторов являются однородными. Если подставить выражение для математической модели в общем виде в , то получим:
Таким образом, Q есть функция (l+1)
переменных
Все возможные математические модели можно разбить на две группы: линейные по отношению к определяемым параметрам bi и нелинейные. Общий вид математических моделей, приводимых к первому виду следующий: где l – количество определяемых параметров, bj – сами коэффициенты, а fj – произвольные функции независимых переменных, не включающие определяемые коэффициенты (отметим, что при этом зависимость от факторов xi может и не быть линейной). В качестве иллюстрации можно привести такие модели:
,
В случае моделей, линейных по отношению к параметрам система уравнений будет являться системой линейных уравнений (см. ниже), которая легко может быть решена соответствующими методами, в том числе и точными – методами Гаусса, Гаусса-Жордана и т. д. Если же модель никакими преобразованиями нельзя привести к линейной форме , то система уравнений для определения параметров модели оказывается нелинейной и для ее решения необходимо использовать различные приближенные (итерационные) процедуры, например, метод Гаусса-Зейделя или Ньютона-Рафсона. В качестве примера моделей, нелинейных по отношению к параметрам, можно привести следующие:
Обсуждение математических алгоритмов нелинейного регрессионного анализа выходит за рамки данного пособия. Рассмотрим более подробно математические модели, линейные по отношению к параметрам. Запишем рассчитанное значение функции для i-го измерения: где fji – значение j-й функции при значениях независимых переменных в i-м эксперименте. После подстановки в выражение для суммы квадратов невязок получим:
Остаточная сумма квадратов является функцией от параметров
математической модели. Для нахождения минимума этой функции необходимо
потребовать одновременное равенство нулю частных производных функции
Q по параметрам
После сокращения на (–2) и перегруппировки получаем:
Полученные таким образом (l + 1)
уравнение образуют систему линейных уравнений для нахождения (l +
1)
параметров математической модели.
Дальнейшие рассуждения показывают, что квадратную матрицу, размерности (l + 1)х(l + 1) в левой части уравнения, называемую информационной матрицей, можно представить как произведение результата транспонирования прямоугольной матрицы
Вектор-столбец в правой части уравнения есть результат умножения транспонированной матрицы FТ на вектор столбец Y, составленный из экспериментально определенных значений целевой функции:
Окончательно получаем матричную форму системы уравнений в виде:
Умножая
слева обе части равенства на матрицу, обратную информационной, называемую матрицей
дисперсий-ковариаций
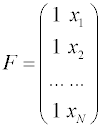
Полученное общее выражение может быть легко использовано для вывода выражений расчета коэффициентов произвольных математической моделей, линейных по отношению к определяемым параметрам. Продемонстрируем использование МНК для нахождения параметров прямолинейной зависимости. Ее математическая модель имеет вид: Сравнивая это выражение и общее выражение для линейной модели, получаем, что f0 = 1, f1 = x. Тогда для N проведенных экспериментов матрица F записывается в виде:
Вектор-столбец
определяемых параметров
матрица дисперсий-ковариаций получается обращением информационной матрицы:
Подставим полученные матрицы в и получим вектор-столбец определяемых коэффициентов:
Верхний элемент вектор-столбца В есть выражение для bo, нижний – для b1.
Легко заметить, что выражение для свободного члена bo может быть записано через значение b1 в более компактной форме:
Статистическая обработка уравнения регрессии Для проведения статистического анализа рассчитанного уравнения регрессии необходимо иметь статистическую оценку свойств определяемого параметра y. Для этого необходимо проводить для каждого сочетания независимых переменных (каждой строки таблицы 1) параллельные измерения и подвергать их статистической обработке, определяя выборочные средние yi и выборочные дисперсии si2 . Если ставилось одинаковое количество из m параллельных опытов, то проверку гипотезы однородности рассчитанных дисперсий зависимой переменной можно проводить по критерию Кохрена. Если гипотеза об однородности дисперсий принимается, то рассчитывается обобщенная дисперсия зависимой переменной
Если гипотеза однородности дисперсий отвергается, то использование уравнения для расчета параметров математической модели невозможно. Необходимо использовать "взвешенный" метод наименьших квадратов, который будет описан ниже. Рассчитанные значения параметров математической модели являются случайными величинами, имеющими распределение Стьюдента с числом степеней свободы равным, как и для дисперсии зависимой переменной, f = N∙(m-1). Дисперсии параметров математической
модели могут быть найдены как диагональные
элементы матрицы дисперсий-ковариаций
Недиагональные элементы этой матрицы - ковариации – есть количественная мера взаимной зависимости определяемых коэффициентов регрессии. Для линейно-независимых параметров ковариации равны нулю. Для рассмотренной нами в качестве примера линейной зависимости дисперсии параметров принимают вид:
число степеней свободы совпадает с числом степеней свободы дисперсии зависимой переменной. Интервальная оценка параметров модели может быть получена умножением среднеквадратичного отклонения параметра на коэффициент Стьюдента для выбранной доверительной вероятности:
Сравнивая рассчитанный доверительный интервал по модулю со значением самого параметра можно проверить гипотезу значимости коэффициента регрессии. Если доверительный интервал окажется по модулю больше значения параметра, то нельзя статистически надежно утверждать, что данный параметр значимо отличается от нуля. Данный параметр (и соответствующее ему слагаемое) можно исключить из модели . Последней стадией статистической обработки рассчитанного уравнения регрессии является проверка адекватности полученного уравнения экспериментальным данным. Для этого по критерию Фишера сравниваются дисперсия воспроизводимости зависимой переменной s2(y) и дисперсия адекватности, рассчитываемая как частное остаточной суммы квадратов
и числа степеней свободы fR = N – l, где N – число экспериментальных точек определения зависимой переменной, а l – количество значимых коэффициентов регрессии.
Если для выбранного уровня значимости дисперсии одинаковы, то регрессионное уравнение адекватно описывает экспериментальные данные. В случае линейной математической модели степень соответствия
экспериментальных величин прямолинейной зависимости можно оценивать с помощью выборочного
коэффициента корреляции r, который
вычисляется через ковариацию зависимой и независимой переменных (
Среднеквадратичные отклонения вычисляются следующим образом.
Для проведения вычисления удобно пользоваться выражением : Коэффициент корреляции обладает следующими свойствами: 1. Коэффициент корреляции может принимать значения в интервале [-1, 1]. 2. Если r < 0, то зависимость y от x является антибатной (убывающая зависимость); если r > 0, то зависимость y от x является синбатной (возрастающая зависимость); 3. Если
модуль коэффициента корреляции равен единице ( Если
Если
Интервальная оценка для условного математического ожидания Рассчитанные коэффициенты регрессии математической модели есть случайные величины, поэтому рассчитанное по полученному в результате применения МНК уравнению значение зависимой переменной
так же будет являться случайной величиной, условное математическое ожидание которой будет равно рассчитанному значению, а дисперсию можно определить по следующему выражению:
Где
- вектор столбец значений
функций fj в математической модели в точке, для которой рассчитывается матожидание и
дисперсия, ХТ – вектор-строка, полученная
транспонированием Х,
Для прямолинейной зависимости в точке x = x0 получим: Условное математическое
ожидание:
Дисперсия:
Добавим и вычтем в числителе
В такой форме записи видно, что дисперсия рассчитанного значения целевой функции принимает минимальное значение в центре области значений независимой переменной (в области среднего арифметического абсцисс x), и возрастает к ее границам. Реализация регрессионного анализа в программе MS Excel Для проведения расчетов по линейному методу МНК можно использовать программу Microsoft Excel (входит в программный пакет Microsoft Office). Наиболее просто реализуется вычисления коэффициентов линейной математической модели типа . Для этого можно использовать следующие встроенные функций MS Excel: ОТРЕЗОК(диапозон_Y;диапазон_X) НАКЛОН(диапазон_Y;диапазон_X) КОРРЕЛ(диапазон_Y;диапазон_X) Первая функция вычисляет свободный член уравнения регрессии (b0 в выражении), вторая – наклон прямой (b1 в выражении ). Третья функция позволяет вычислить коэффициент корреляции r. Каждая из функций принимает два аргумента, разделяемых знаком точка с запятой “;”. Каждый из аргументов определяет диапазон ячеек, в котором находятся значения зависимой (диапазон_Y) и независимой (диапазон_Х) переменных. Диапазоны должны быть одинаковой формы (вектор-строка или вектор-столбец одинаковой длины). В более общем виде линейный МНК может быть реализован с помощью встроенной функции ЛИНЕЙН, которая производит вычисления коэффициентов регрессии линейной математической модели с несколькими переменными типа и дополнительно рассчитывает ряд статистических показателей. Вычисленные коэффициенты регрессии и статистики возвращаются в виде массива чисел. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Запишем модель в следующем виде:
Функция ЛИНЕЙН может принимать от одного до четырех аргументов. Обязателен только первый аргумент, остальные – необязательные: ЛИНЕЙН(диапазон_Y, [диапазон_X], [константа], [статистика])
Диапазон_Y - Обязательный аргумент. Диапазон ячеек, содержащий множество значений зависимой переменной (y); Диапазон_Х - Диапазон ячеек, содержащий множество значений независимых переменных. Если переменных несколько, то они должны располагаться в смежных ячейках. Каждое диапазон значений независимой переменной должен иметь форму, аналогичную диапазону_Y. Константа. Необязательный аргумент. Логическое значение, которое указывает, требуется ли, чтобы константа b0 была равна 0. Если аргумент константа имеет значение ИСТИНА или опущен, то свободный член b0 вычисляется обычным образом. Если аргумент константа имеет значение ЛОЖЬ, то значение b0 полагается равным 0 и значения коэффициентов регрессии подбираются с этим условием. Статистика. Необязательный аргумент. Логическое значение, которое указывает, требуется ли возвратить дополнительную регрессионную статистику. Если аргумент статистика имеет значение ИСТИНА, функция ЛИНЕЙН возвращает дополнительную регрессионную статистику. Возвращаемый массив чисел будет иметь следующий вид:
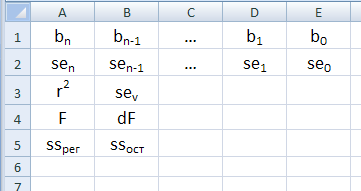
1. Если статистика=ЛОЖЬ, то 1 строка и n столбцов (n-число определяемых параметров) 2. Если статистика=ИСТИНА, то 5 строк и n столбцов. Описание значений, вычисляемых функцией, приведены в таблице ниже.
|

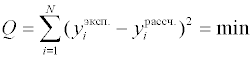
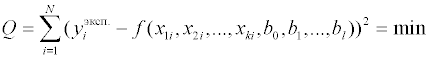
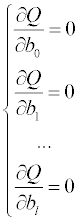
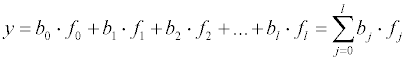 ,
,
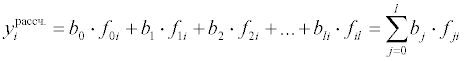 ,
,
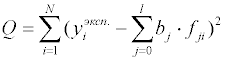
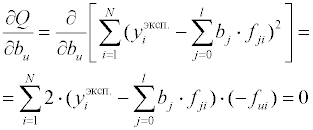
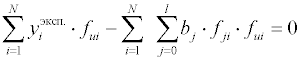
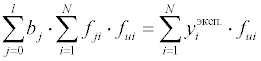 ,
u = 0, 1, …, l
,
u = 0, 1, …, l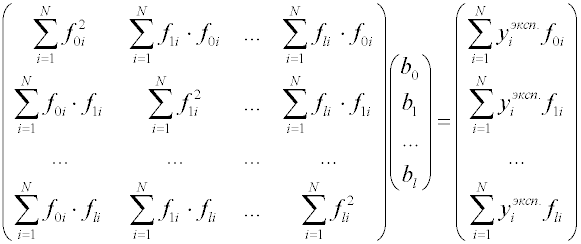
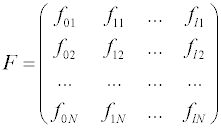 размерностью
N x (
размерностью
N x (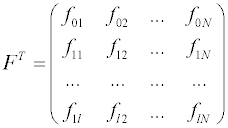
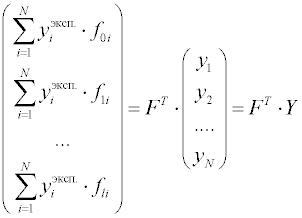
 ,
,
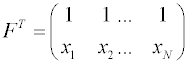 ,
,
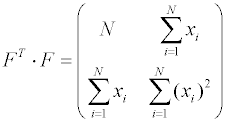
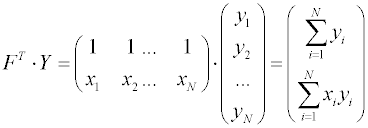
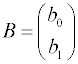 ,
,
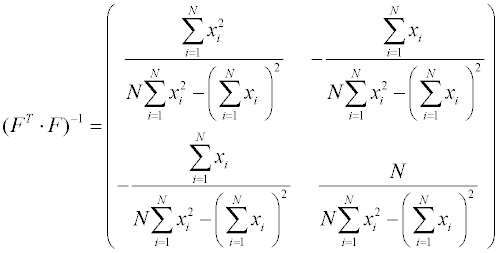
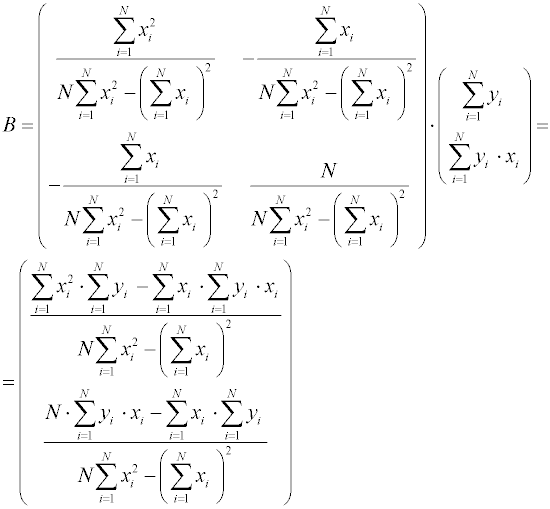
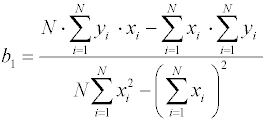
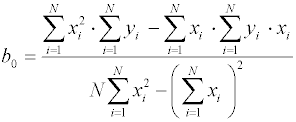
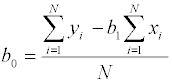
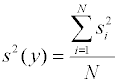 . Число
степеней свободы
. Число
степеней свободы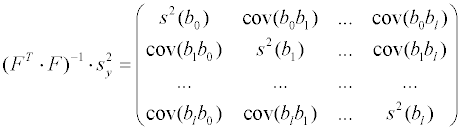
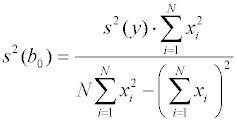
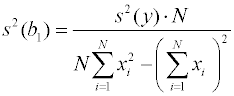 ,
, 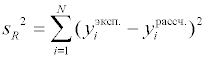
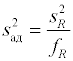
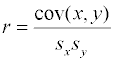
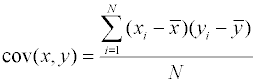
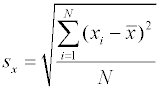
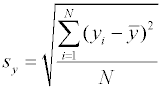
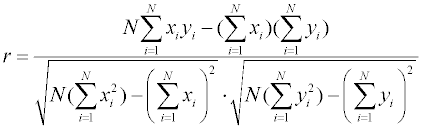
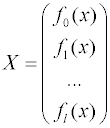
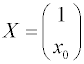 ,
,
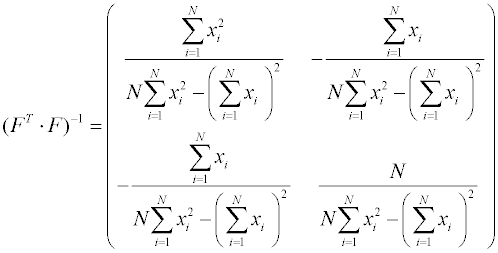

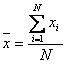 - среднее
арифметическое значений независимой переменной и, после замены
- среднее
арифметическое значений независимой переменной и, после замены
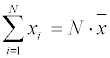 и
перегруппировки получим
и
перегруппировки получим